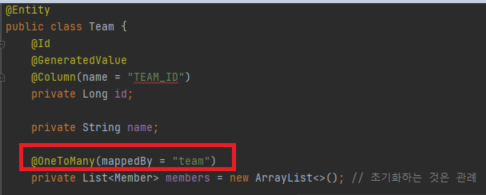
1:N인 관계를 양방향 연관관계로 구현해서 Postman으로 API 테스트를 진행하는데 놀랍게도 StackOverFlowError가 발생하였다.
그 유명한 StackOverFlow를 처음으로 맞이해서 매우 반갑긴 하였지만, 해결할 생각에 막막하기만 했다.
열심히 구글링한 결과 JPA 순환 참조라는 것을 알았다.
Employee.java
public class Employee {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "employee_id")
private Long id;
private String employeeName;
private String phoneNumber;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "shop_id")
private Shop shop;
}
Shop.java
public class Shop {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "shop_id")
private Long id;
private String shopName;
private String phoneNumber;
@OneToMany(mappedBy = "shop", cascade = CascadeType.ALL)
private List employees = new ArrayList<>();
}원인은 Controller를 통해서 Shop Entity를 Response로 내보내고 브라우저에 json 형태로 뿌려주기 위해서는 Shop entity가 참조하고 있는 Employee Entity도 함께 불러오게 된다. 여기서 순환 참조가 발생한다!
Employee Entity도 Shop Entity를 참조하기 때문이다.
해결방법
1. @JsonManagedReference, @JsonBackReference 애노테이션 사용
- 순환참조를 방어하기 위한 Annotation이다. 부모 클래스에 @JsonManagedReference 자식 클래스에 @JsonBackReference 애노테이션을 붙여준다.
예) 1:N관계에서 1인 Entity에 @JsonManagedReference N인 Entity에 @JsonBackReference 애노테이션 붙인다.
Employee.java
public class Employee {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "employee_id")
private Long id;
private String employeeName;
private String phoneNumber;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "shop_id")
@JsonBackReference
private Shop shop;
}
Shop.java
public class Shop {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "shop_id")
private Long id;
private String shopName;
private String phoneNumber;
@OneToMany(mappedBy = "shop", cascade = CascadeType.ALL)
@JsonManagedReference
private List employees = new ArrayList<>();
}
2. @JsonIgnore
- json 데이터에 해당 프로퍼티는 null로 들어가게 된다. 해당 데이터를 아예 포함이 안되게 하는 것이다.
3. DTO 사용
- 해당 문제는 Entity 자체를 리턴하는 데에서 문제가 발생한 것이다. Entity 자체를 리턴하는 것보다 ResponseDto를 생성해서 필요한 데이터만 리턴하는 게 더 좋은 설계라고 생각된다. Entity는 그 자체로 두고 최대한 건드리지 않는 것이 좋다. 많은 애노테이션(제약조건 애노테이션 등)을 Entity Class에 넣다 보니 Entity Class가 너무 복잡해진다. 이번 계기로 리턴할 경우 ResponseDto를 만들고 url 파라미터를 받는 경우에도 FormDataDto 등을 생성해서 Entity에는 최대한 DB 관련 애노테이션만 넣을 수 있도록 해야겠다.
4. 단방향, 양방향 매핑 고민
- 아무 고민 없이 양방향 매핑으로 구현을 하였지만, 정말로 양방향으로 매핑이 필요한지 고민하고 단방향 매핑을 이용하는 것도 해당 문제를 해결하는 데 방법이다.
'JPA' 카테고리의 다른 글
| JPA 연관관계 매핑 기초 (0) | 2021.06.17 |
|---|---|
| JPA 엔티티 매핑 (0) | 2021.06.08 |
| JPA 영속성 관리 (0) | 2021.06.06 |
| JPA 소개 (0) | 2021.06.04 |