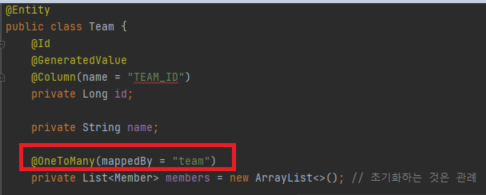
public class Member {
private String memberId;
pirvate String name;
...
}
INSERT INTO MEMBER(MEMBER_ID, NAME) VALUES
SELECT MEMBER_ID, NAME FROM MEMBER M
UPDATE MEMBER SET ...
어느날 갑자기 요청사항으로 전화번호 칼럼 추가 요청이 오면 관련 테이블에 모두 수정 필요
public class Member {
private String memberId;
pirvate String name;
private String tel; // 추가
...
}
INSERT INTO MEMBER(MEMBER_ID, NAME, TEL) VALUES // TEL 추가
SELECT MEMBER_ID, NAME, TEL FROM MEMBER M // TEL 추가
UPDATE MEMBER SET ... TEL = ? // TEL 추가
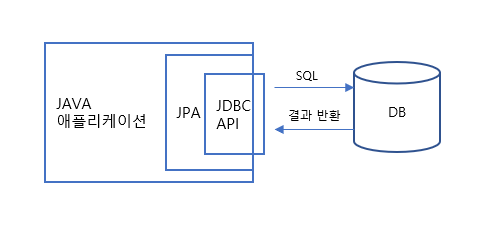
SQL에 의존적인 개발을 피하기 어렵다.
패러다임의 불일치! (객체 VS 관계형 데이터베이스)
객체와 관계형 데이터베이스의 차이
1. 상속
2. 연관관계
3. 데이터 타입
4. 데이터 식별 방법
1) 객체다운 모델링으로 개발
class Member {
String id;
Team team; // 참조로 연관관계 맺는다.
String username;
Team getTeam() {
return team;
}
}
class Team {
Long id;
String name;
}
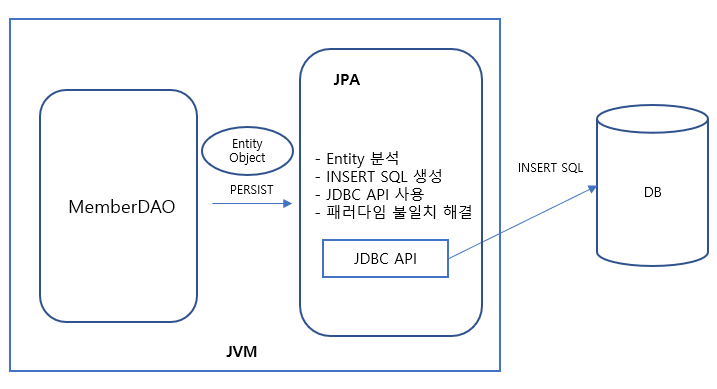
2) 객체 모델링 저장
member.getTeam().getId(); 를 이용해서 TEAM_ID에 넣는다.
INSERT INTO MEMBER(MEMBER_ID, TEAM_ID, USERNAME) VALUES ...
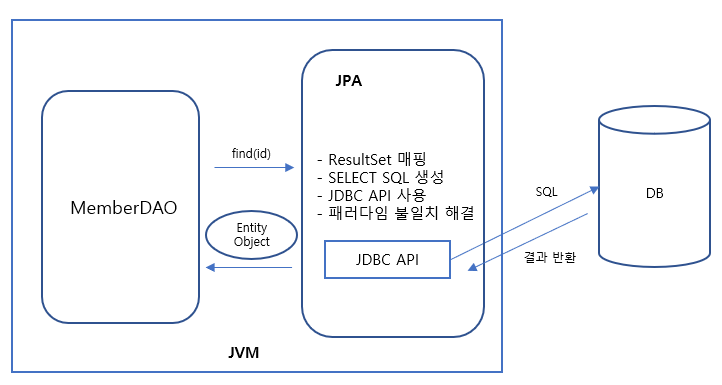
3) 객체 모델링 조회
객체다운 설계를 하여 조회를 하는데 오히려 복잡하고 맵핑 작업 시간이 더 걸려 결국엔 슈퍼 DTO 객체를 만들게 된다.
SELECT M.*, T.*
FROM MEMBER M
JOIN TEAM T ON M.TEAM_ID = T.TEAM_ID
public Member find(String memberId) {
// SQL 실행 ...
Member member = new Member();
// 데이터베이스에서 조회한 회원 관련 정보를 모두 입력
Team team = new Team();
// 데이터베이스에서 조회한 팀 관련 정보를 모두 입력
// 회원과 팀 관계 설정
member.setTeam(team);
return member;
}
4) 처음 실행하는 SQL에 따라 탐색 범위 결정되는 경우
SELECT M.*, T.*
FROM MEMEBER M
JOIN TEAM T ON M.TEAM_ID = T.TEAM_ID
member.getTeam(); // ok
member.getOrder(); // null 처음에 맴버과 팀만 가져왔기 때문에.. 마음대로 사용자가 주문한 order 호출할 수가 없다..
만약에 memberDAO.find()를 다른 개발자가 개발했다면
엔티티 신뢰 문제 발생.. 개발자가 직접 눈으로 확인하지 않은 이상은 신뢰하고 사용하기 힘들다.
class MemberService {
...
public void provess() {
Mmber member = memberDAO.find(memberId);
member.getTeam(); // ???
member.getOrder().getDelivery(); // ???
}
Member member = MemberDAO.find(memberId); => SELECT * FROM MEMBER
Team team = member.getTeam();
String teamName = team.getName(); => SELECT * FROM TEAM
즉시 로딩 : JOIN SQL로 한번에 연관된 객체까지 미리 조회
Member member = MemberDAO.find(memberId); => SELECT M.*, T.* FROM MEMBER JOIN TEAM ...
Team team = member.getTeam();
String teamName = team.getName();
** ORM은 객체와 RDB 두 기둥위에 있는 기술
** JPA 사용하기 전 과거로 돌아가고 싶지않다. (JPA 사용하는 어느 개발자가..)
- 개발 인생에서 많은 시간을 SQL 생성하는데 투자하는데 그 시간을 아껴 더 좋은 코드를 생산할 수 있다.
ListItemReader 객체를 사용하면 모든 데이터를 한번에 가져와 메모리에 올려놓고 read() 메서드로 하나씩 배치 처리 작업을 수행할 수 있습니다.
그런데 수백, 수천을 넘어 수십만 개 이상의 데이터를 한번에 가져와 메모리에 올려놓아야 할 때는 어떻게 해야 할까요?
이때는 배치 프로젝트에서 제공하는 PagingItemReader 구현체를 사용할 수 있습니다.
구현체는 크게 JdbcPagingItemReader, JpaPagingItemReader, HibernatePagingItemReader가 있습니다.
JpaPagingItemReader를 사용해보겠습니다.
JpaPagingItemReader에는 지정한 데이터 크기만큼 DB에서 읽어오는 setPageSize() 메서드 기능이 있습니다.
데이터를 지정한 단위로 가져와 배치 처리를 수행할 수 있습니다.
1. @Bean(destroyMethod="") -> 스프링에서 destroyMethod를 사용해 삭제할 빈을 자동으로 추적합니다.
destoryMethod=""와 같이 하여 기능을 사용하지 않도록 설정하면 실행 시 출력되는 warning 메시지를 삭제할 수 있습니다.
2. jpaPagingItemReader.setQueryString() -> jpaPagingItemReader를 사용하려면 쿼리를 직접 짜서 실행하는 방법밖에 없습니다.
3. jpaPagingItemReader.setParameterValues(map) -> updatedDate, status 파라미터를 Map에 추가해 사용할 파라미터를 설정합니다.
JpaPagingItemReader 주의사항
inacticeJobStep()에서 설정한 청크 단위(커밋 단위)가 5라고 가정하면 Item5개를 writer까지 배치 처리를 진행하고 저장한다고 해봅시다. 저장된 데이터를 바탕으로 다음에 다시 지정한 크기로 새 인덱스를 할당해 읽어 와야 하는데 이전에 진행한 5라는 인덱스값을 그대로 사용해 데이터를 불러오도록 로직이 짜여 있어서 문제가 됩니다.
예를 들어 청크 단위로 Item 5개를 커밋하고 다음 청크 단위로 넘어가야 하는 경우를 가정하겠습니다.
하지만 entityManager에서 앞서 처리된 Item 5개 때문에 새로 불러올 Item의 인덱스 시작점이 5로 설정되어 있게 됩니다. 그러면 쿼리 요청 시 offset 5(인덱스값), limit 5(지정한 크기 단위)이므로 개념상 바로 다음 청크 단위(Item 5개)인 Item을 건너뛰는 상황이 발생합니다.
이러한 상황에서 가장 간단한 해결 방법은 조회용 인덱스값을 항상 0으로 반환하는 겁니다.
0으로 반환하면 Item 5개를 수정하고 다음 5개를 건너뛰지 않고 원하는 순서/청크 단위로 처리가 가능해집니다.
1.2 다양한 ItemWriter 구현 클래스
JpaItemWriter는 별도로 저장 설정을 할 필요 없이 제네릭에서 저장할 타입을 명시하고 EntityManagerFactory만 설정하면 Processor에서 넘어온 데이터를 청크 단위로 저장합니다.
1.3 JobParameter 사용하기
테스트 코드에 JobParameter를 생성해 JobLauncher에 전달하게끔 수정합니다.
1. new Date(); -> Date 타입은 JobParameter에서 허용하는 파라미터 중 하나입니다.
JobParametersBuilder를 사용하면 간편하게 JobParameters를 생성할 수 있습니다. JobParameters는 여러 JobParameter를 받는 객체입니다. JobLauncher를 사용하려면 JobParameters가 필요합니다.
1.4 테스트 시에만 H2 DB를 사용하도록 설정하기
@AutoConfigureTestDatabase(connection = EmbeddedDatabaseConnection.H2) 어노테이션을 사용하면 테스트 시에는 H2를 할당하게 처리할 수 있습니다.
1.5 청크 지향 프로세싱
청크 지향 프로세싱은 트랜잭션 경계 내에서 청크 단위로 데이터를 읽고 생성하는 프로그래밍 기법입니다.
청크란 아이템이 트랜잭션에서 커밋되는 수를 말합니다.
read한 데이터 수가 지정한 청크 단위와 일치하면 wirte를 수행하고 트랜잭션을 커밋합니다.
청크 지향 프로세싱의 이점은 1000여 개의 데이터에 대해 배치 로직을 실행한다고 가정합시다. 청크로 나누지 않았을 때는 하나만 실패해도 다른 성공한 999개의 데이터가 롤백됩니다. 그런데 청크 단위를 10으로 해서 배치 처리를 하면 도중에 배치 처리에 실패하더라도 다른 청크는 영향을 받지 않습니다.
1.6 배치의 인터셉터 Listener 설정하기
배치 흐름에서 전후 처리를 하는 Listener를 설정할 수 있습니다.
구체적으로 Job의 전후 처리, Step의 전후 처리, 각 청크 단위에서의 전후 처리 등 세세한 과정 실행 시 특정 로직을 할당해 제어할 수 있습니다.
스프링 배치에서는 Job의 Listener로 JobExecutionListener 인터페이스를 제공합니다.
1. @Slf4j -> 필드에 로그 객체를 따로 생성할 필요 없이 로그 객체를 사용할 수 있도록 설정하는 롬복 어노테이션
- Job 설정에 Listener 등록하기
InactiveUserJobConfig.java
1.7 어노테이션 기반으로 Listener 설정하기
InacticeStepListener.java
- Step 설정에 Listener 등록하기
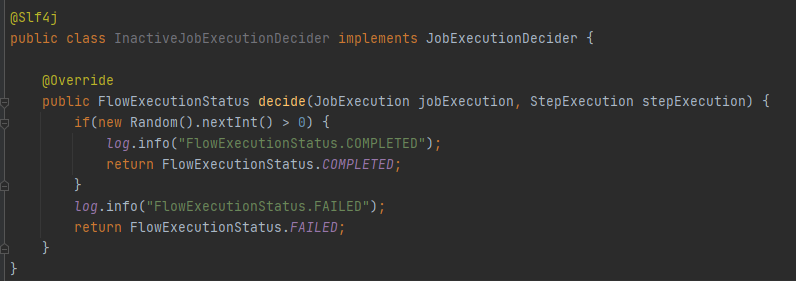
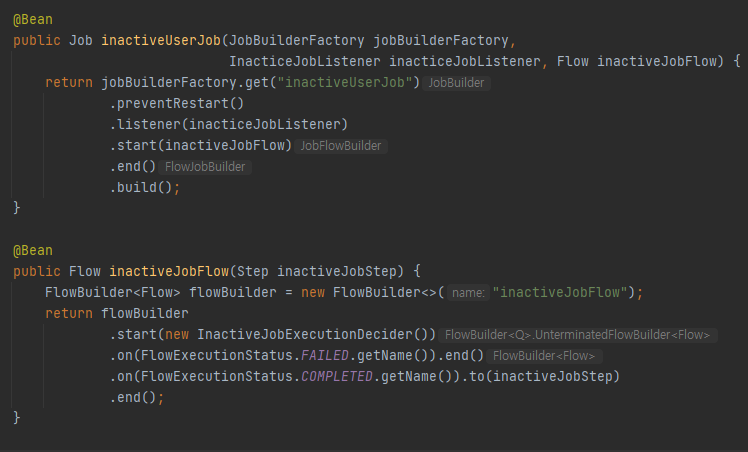
1.8 Step의 흐름을 제어하는 Flow
스프링 배치는 세부적인 조건에 대한 흐름을 제어하는 Flow를 제공합니다.
흐름에서 조건에 해당하는 부분을 JobExecutionDecider 인터페이스를 사용해 구현할 수 있습니다.
스프링 부트 배치의 반복되는 작업 프로세스를 이해하면 비즈니스 로직에 집중할 수 있습니다.
스프링 부트 배치 주의사항
1. 가능하면 단순화해서 복잡한 구조와 로직을 피해야 합니다.
2. 데이터를 직접 사용하는 작업이 빈번하게 일어나므로 데이터 무결성을 유지하는 유효성 검사 등의 방어책이 있어야 합니다.
3. 배치 처리 시 시스템 I/O 사용을 최소화해야 합니다. 잦은 I/O로 데이터베이스 커넥션과 네트워크 비용이 커지면 성능에 영향을 줄 수 있기 때문입니다. 따라서 가능하면 한번에 데이터를 조회하여 메모리에 저장해두고 처리를 한 다음, 그 결과를 한번에 데이터베이스에 저장하는 것이 좋습니다.
4. 일반적으로 같은 서비스에 사용되는 웹, API, 배치, 기타 프로젝트들은 서로 영향을 줍니다. 따라서 배치 처리가 진행되는 동안 다른 프로젝트 요소에 영향을 주는 경우가 없는지 주의를 기울여야 합니다.
5. 스프링 부트 배치는 스케줄러를 제공하지 않습니다. 배치 처리 기능만 제공하며 스케줄링 기능은 스프링에서 제공하는 쿼츠 프레임워크(Quartz Framework), IBM 티볼리(Tivoli) 스케줄러, BMC 컨트롤-M(Control-M) 등을 이용해야 합니다. 리눅스 crontab 명령은 가장 간단히 사용할 수 있지만 이는 추천하지 않습니다. crontab의 경우 각 서버마다 따로 스케줄링을 관리해야 하며 무엇보다 클러스터링 기능이 제공되지 않습니다. 반면에 쿼츠와 같으 ㄴ스케줄링 프레임워크를 사용한다면 클러스터링뿐만 아니라 다양한 스케줄링 기능, 실행 이력 관리 등 여러 이점을 얻을 수 있습니다.
2. 스프링 부트 배치 이해하기
1. 읽기(read) - 데이터 저장소(알반적으로 데이터베이스)에서 특징 데이터 레코드를 읽습니다.
2. 처리(processing) - 원하는 방식으로 데이터를 가공/처리합니다.
3. 쓰기(write) - 수정된 데이터를 다시 저장소 (데이터베이스)에 저장합니다.
Job과 Step은 1:M, Step과 ItemReader, ItemProcessor, ItemWriter는 1:1의 관계를 가집니다. 즉, Job이라는 하나의 큰 일감(Job)에 여러 단계(Step)를 두고, 각 단계를 배치으 기본 흐름대로 구현합니다.
Job
Job은 배치 처리 과정을 하나의 단위로 만들어 표현한 객체입니다. 또한 전체 배치 처리에 있어 항상 최상단 계층에 있습니다. 위에서 하나의 Job(일감) 안에는 여러 Step(단계)이 있다고 설명했던 바와 같이 스프링 배치에서 Job 객체는 여러 Step 인스턴스를 포함하는 컨테이너입니다.
Job 객체를 만드는 빌더는 여러 개 있습니다. 여러 빌더를 통합 처리하는 공정인 JobBuilderFactory로 원하는 Job을 손쉽게 만들 수 있습니다. JobBuilderFactory의 get() 메소드로 JobBuilder를 생성하고 이를 이용합니다.
Step
Step은 실질적인 배치 처리를 정의하고 제어하는 데 필요한 모든 정보가 들어 있는 도메인 객체입니다.
Job을 처리하는 실질적인 단위로 쓰입니다. 모든 Job에는 1개 이상의 Step이 있어야 합니다.
JobRepository
JobRepository는 배치 처리 정보를 담고 있는 매커니즘(어떠한 사물의 구조, 또는 그것이 작동하는 원리)입니다. 어떤 Job이 실행되었으며 몇 번 실행되었고 언제 끝났는지 등 배치 처리에 대한 메타데이터를 저장합니다. 예를 들어 Job 하나가 실행되면 JobRepository에서는 배치 실행에 관련된 정보를 담고 있는 도메인인 JobExecution을 생성합니다.
JobRepository는 Step의 실행 정보를 담고 있는 StepExcution도 저장소에 저장하며 전체 메타데이터를 저장/관리하는 역할을 수행합니다.
JobLauncher
JobLauncher는 Job, JobParameters와 함께 배치를 실행하는 인터페이스입니다. 인터페이스의 메서드는 run() 하나입니다.
ItemReader
ItemReader는 Step의 대상이 되는 배치 데이터를 읽어오는 인터페이스입니다. FILE, XML, DB 등 여러 타입의 데이터를 읽어올 수 있습니다.
ItemProcessor
ItemProcessor는 ItemReader로 읽어온 배치 데이터를 변환하는 역할을 수행합니다.
굳이 ItemWriter에 변환하는 로직을 넣을 수도 있는데 왜 ItemProcessor를 따로 제공할까요? 그 이유는 두 가지입니다.
첫 번째 이유는 비즈니스 로직을 분리하기 위해서입니다. ItemWriter는 저장만 수행하고, ItemProcessor는 로직 처리만 수행해 역할을 명확하게 분리합니다.
두 번째 이유는 읽어온 배치 데이터와 쓰여질 데이터의 타입이 다를 경우에 대응하기 위해서입니다.
ItemWriter
ItemWriter는 배치 데이터를 저장합니다. 일반적으로 DB나 파일에 저장합니다.
3. 스프링 부트 휴먼회원 배치 설계하기
전체 배치 프로세스
1. H2 DB에 저장된 데이터 중 1년간 업데이트되지 않은 사용자를 찾는 로직을 ItemReader로 구현합니다.
2. 대상 사용자 데이터의 상탯값을 휴먼회원으로 전환하는 프로세스를 ItemProcessor에 구현합니다.
3. 상탯값이 변한 휴먼회원을 실제로 DB에 저장하는 ItemWriter를 구현합니다.
4. 스프링 부트 배치 설정하기
스프링 부트 배치 스타터를 사용하면 배치 생성에 필요한 많은 설정을 자동으로 적용할 수 있습니다.
1. @EnableBatchProcessing은 스프링 부트 배치 스타터에 미리 정의된 설정들을 실행시키는 마법의 어노테이션입니다.
배치에 필요한 JobBuilder, StepBuilder, JobRepository, JobLauncher 등 다양한 설정이 자동으로 주입됩니다.
2. Job 실행에 필요한 JobLauncher를 필드값으로 갖는 JobLauncherTestUtils를 빈으로 등록합니다.
휴먼 전환이 올바르게 되었는지 확인하는 테스트 코드를 먼저 작성합니다.
1. jobLauncherTestUtils.launchJob() -> launchJob() 메서드로 Job을 실행시켰습니다. launchJob() 메서드의 반환값으로 실행 결과에 대한 정보를 담고 있는 JobExecution이 반환됩니다.
2. jobExecution.getStatus() -> getStatus() 값이 COMPLETED로 출력되면 Job의 실행 여부 테스트는 성공입니다.
3. findByUpdatedDateBeforeAndStatusEquals -> 업데이트된 날짜가 1년 전이며 상태값이 ACTIVE인 사용자들이 없어야 휴먼회원 배치 테스트가 성공입니다.
- 휴먼회원 검색 쿼리 생성
5.2 휴먼회원 배치 정보 설정
1. 휴먼회원 Job 설정
2. 휴먼회원 Step 설정
3. 휴먼회원 Reader, Processor, Writer 설정
배치 정보는 @Configuration 어노테이션을 사용하는 설정 클래스에 빈으로 등록합니다. jobs 패키지를 새로 만들어 InactiveUserJobConfig 클래스를 생성합니다.
inacticeUserJobConfig.java
1. JobBuilderFactory jobBuilderFactory -> Job 생성을 직관적이고 편리하게 도와주는 빌더인 JobBuilderFactory를 주입했습니다. 빈에 주입할 객체를 파라미터로 명시하면 @Autowired 어노테이션을 쓰는 것과 같은 효과가 있습니다.
2. get("inactiveUserJob") -> inactiveUserJob 이라는 이름의 JobBuilder를 생성하며, preventRestart()는 Job의 재실행을 막습니다.
3. start(inactiveJobStep)은 파라미터에서 주입받은 휴먼회원 관련 Step인 inactiveJobStep을 제일 먼저 실행하도록 설정하는 부분입니다. inactiveJobStep은 앞선 inactiveUserJob과 같이 InactiveUserJobConfig 클래스에 빈으로 등록할 겁니다.
inacticeUserJobConfig.java
1. <User, User> chunk(10) -> 제네릭을 사용해 chunk()의 입력 타입과 출력 타입을 User 타입으로 설정했습니다. chunk의 인잣값은 10으로 설정했는데 쓰기 시에 청크 단위로 묶어서 writer() 메서드를 실행시킬 단위를 지정한 겁니다. 즉, 커밋의 단위가 10개입니다.
2. Step의 reader, processor, writer를 각각 설정했습니다.
inacticeUserReader()
inacticeUserJobConfig.java
1. @StepScope -> 기본 빈 생성은 싱글턴이지만 @StepScope를 사용하면 해당 메서드는 Step의 주기에 따라 새로운 빈을 생성합니다. 즉, 각 Step의 실행마다 새로 빈을 만들기 때문에 지연 생성이 가능합니다. 주의할 사항은 @StepScope는 기본 프록시 모드가 반환되는 클래스 타입을 참조하기 때문에 @StepScope를 사용하면 반드시 구현된 반환 타입을 명시해 반환해야 한다는 겁니다.
QueueItemReader
QueueItemReader.java
ItemReader의 기본 반환 타입은 단수형인데 그에 따라 구현하면 User 객체 1개씩 DB에 select 쿼리를 요청하므로 매우 비효율적인 방식이 될 수 있습니다.
1. QueueItemReader를 사용해 휴먼회원으로 지정될 타깃 데이터를 한번에 불러와 큐에 담아놓습니다.
2. read() 메서드를 사용할 때 큐의 poll() 메서드를 사용하여 큐에서 데이터를 하나씩 반환합니다.
inacticeUserProcessor()
데이터를 DB에서 읽어와 QueueItemReader에 저장하였으므로 이제 읽어온 타깃 데이터를 휴면회원으로 전환시키는 processor를 만들어보겠습니다.
inacticeUserJobConfig.java
inacticeUserWriter()
휴먼회원을 DB에 저장하는 inacticeUserWriter
inacticeUserJobConfig.java
BatchApplication.java
JobBuilderFactory, StepBuilderFactory를 자동으로 주입받기 위해서는 애플리케이션ㄴ 구동하는 BatchApplication 클래스에 @EnableBatchProcessing 어노테이션을 빈으로 등록하여야 한다.
@EnableBatchProcessing - 배치 작업에 필요한 빈을 미리 등록하여 사용할 수 있도록 해준다.
BatchApplication.java
5.3 SQL로 테스트 데이터 주입하기
SQL 파일을 이용해 테스트 데이터를 생성하여 저장이 가능합니다.
/resources 하위 경로에 import.sql 파일을 생성해놓으면 스프링 부트가 실행될 때 자동으로 해당 파일의 쿼리를 실행합니다. 더 정확히 구분해 말하자면 import.sql은 하이버네이트가, data.sql은 스프링 JDBC가 실행합니다.